BABY NAMES FOR ANALYTICAL PARENTS
- by Georges Duverger
- Naming things is known to be one of the hardest problems in computer science. Naming humans is harder. While naming a child is no job for a machine, we can inform that decision by analyzing the frequency of given names over the years.
- Whether explicit or implicit, a lot of factors influence the name of a baby. How many syllables does it have? Does it go well with your surname? Did you know someone with that name growing up and, more importantly, did you like that person?
- The answers to many of those questions vary a lot for each family but there is one set of questions that data can help us answer unambiguously: how popular (i.e., frequently encountered) has a name been over the years; how popular is it now; how popular will it (likely) be in the future?
- For example, let's look at my (Americanized) first name, George, in the Top 100 American male 1-2-and-3-syllable names dataset:
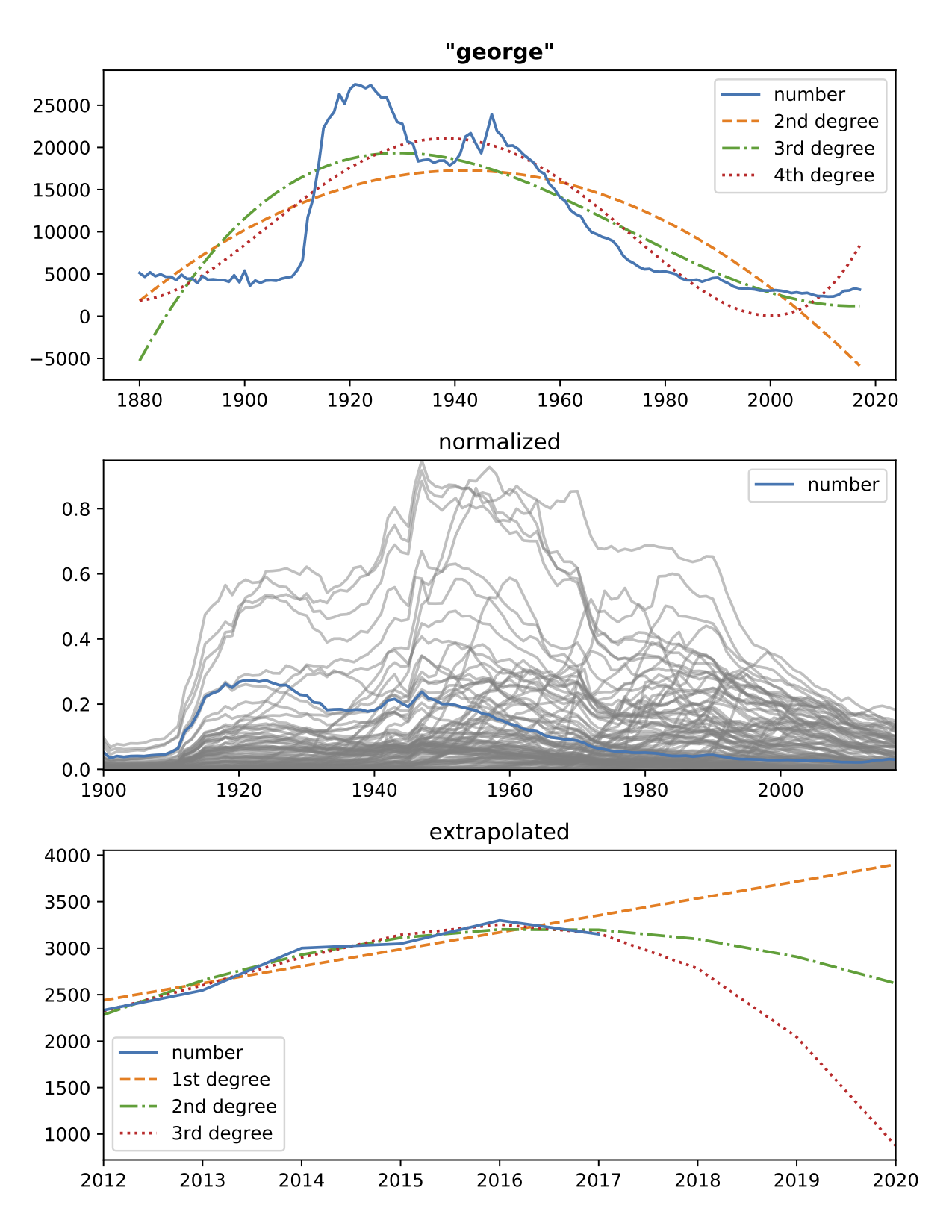
- The top graph represents the number of births (y-axis) at each year (x-axis). The middle graph is the normalization over the whole set. And the bottom graph is the extrapolation for the next couple of years. The orange, green, and red curves are the polynomial regressions of 1st, 2nd, 3rd, and 4th degree.
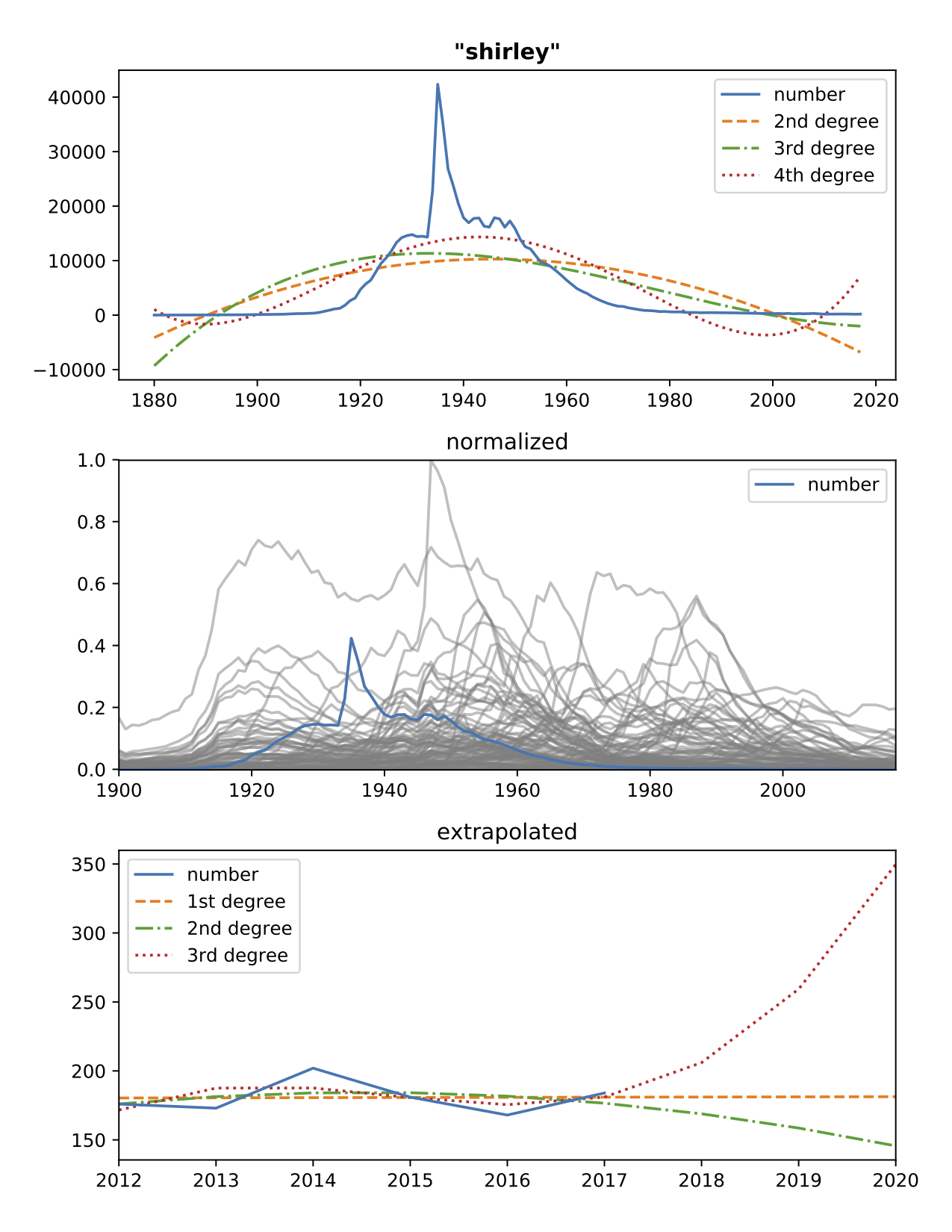
- Now, let's look at more interesting plots, such as the name Shirley peaking in 1935 maybe due to the child actress Shirley Temple starting her career that year:
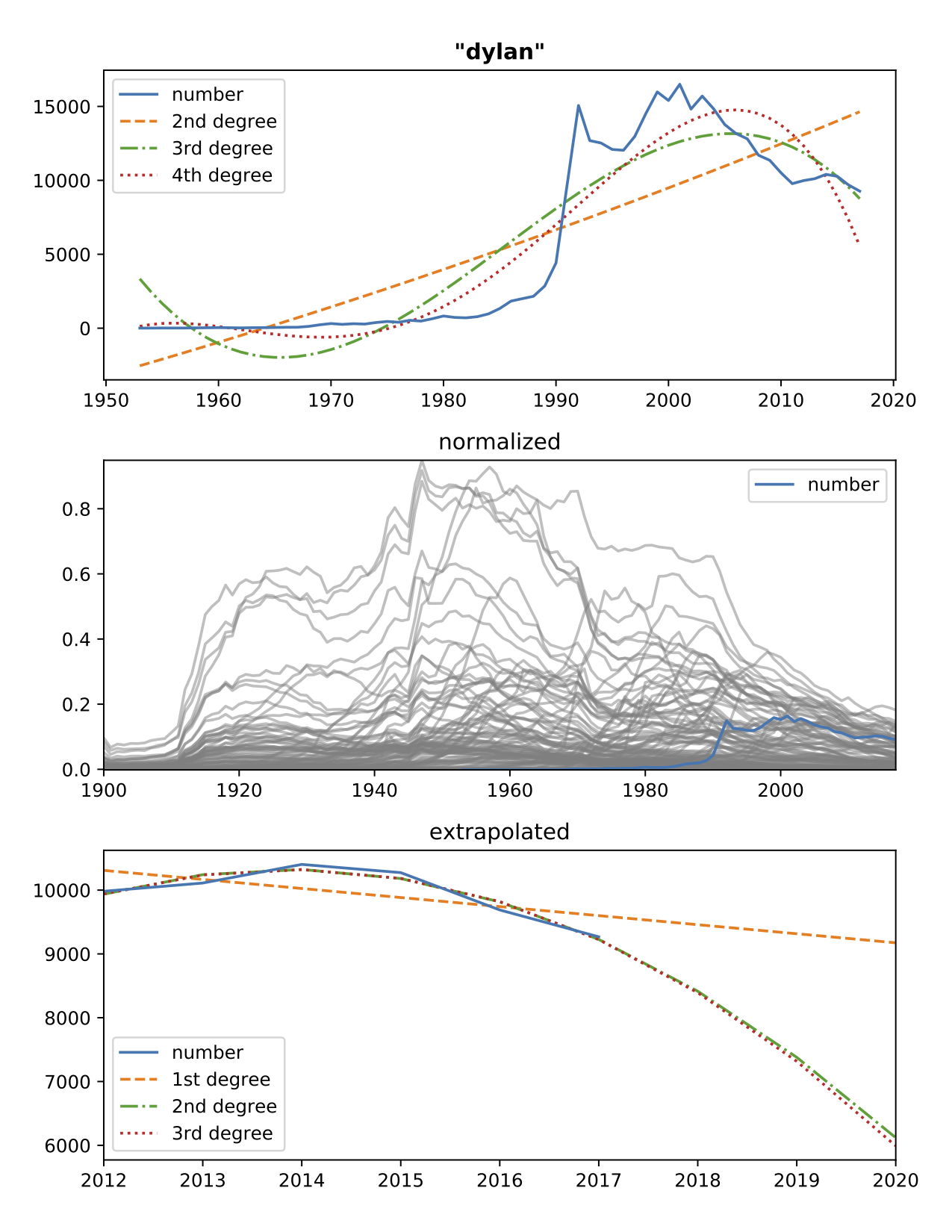
- Or the name Dylan spiking in the early 90's maybe due to the debut of the fictional character Dylan McKay from the television series Beverly Hills, 90210:
- With that type of information, analytical parents can now make the conscious choice to pick an oldie-but-goodie, an about-to-be-rediscovered, or a bandwagon-y name for their offspring.
- Over the last few weeks, I generated PDF reports of specific datasets for expecting friends. I also printed out booklets to make the browsing of names more convenient. All of it is still experimental but, feel free to reach out if you are interested in a custom report.
- For reference, the data comes from the “National Data on the relative frequency of given names in the population of U.S. births where the individual has a Social Security Number” (SSA). France also makes available a “Fichier des prénoms” (Insee) as does the UK (ONS).
- Additionally, if you would like to read more analyses like this one, here is a list of articles that greatly inspired mine:
- How to Name a Baby (WaitButWhy)
- Trendiest baby names in the Social Security database (determined with an analytical chemistry technique) (prooffreader.com)
- The Most Trendy Names in US History (FlowingData)
- Made in Arlington, MA. Generated with Ivy. Styled with Backslash. All emojis designed by OpenMoji – the open-source emoji and icon project. License: CC BY-SA 4.0